Spent the last 4 days making a PWA offline-capable.
— Judah Gabriel 🇮🇱 יהודה גבריאל (@JudahGabriel) June 15, 2022
Tricky, as it’s a viewer of cloud documents. (Guitar chord charts)
Workbox recipes, custom Workbox plugins, IndexDB to mirror backend API, pseudo full text search via IDB indexes, phew!
Learned a lot! Blog forthcoming.
You can build web apps (really, fancy websites) that work offline. When you build one of these things, you can put your device into airplane mode, open your browser and navigate to your URL, and it’ll just work. Pretty cool!
This is the promise of Progressive Web Apps (PWAs): you can build web apps that work like native apps, including ability to run offline.
I’ve built simple offline PWAs in the past, and things worked fairly well.
But this week I needed to do something trickier.
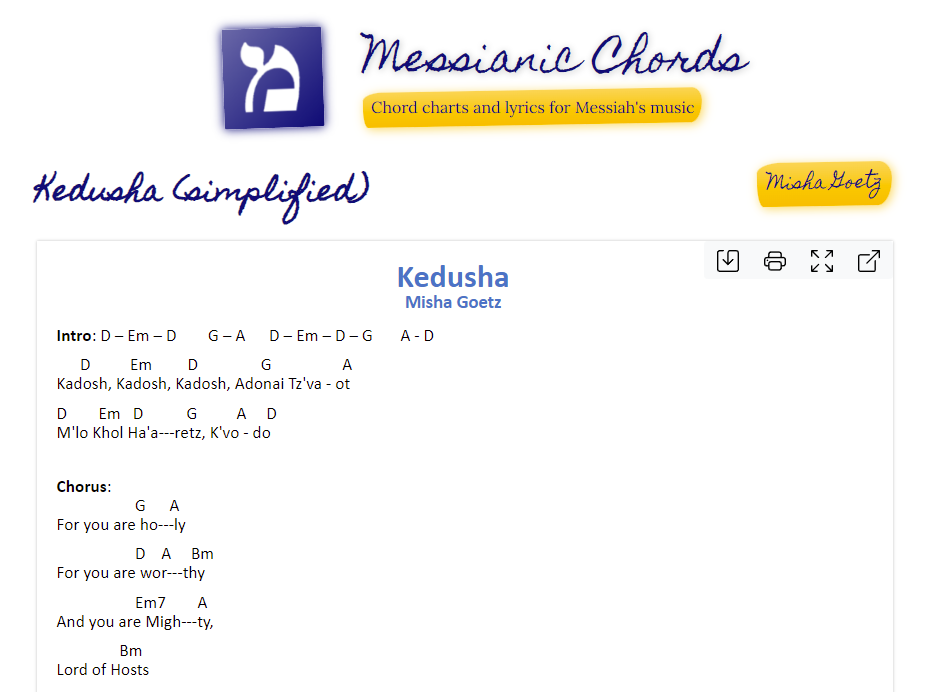
I run MessianicChords.com, a guitar chord chart site for Messianic Jewish music, and I needed to make it work offline. I would soon be traveling to a Messianic music festival where there’s little to no internet connection , and, as a guitar player myself, I wanted to bring up MessianicChords and access the chord charts even while offline.
So I figured, let’s make MessianicChords work entirely offline. Fun!
But this was trickier and a real test of the web platform’s offline capabilities:
- Lots of content. My site has thousands of chord charts, totalling in the hundreds of MB. I can’t just cache everything all at once.
- iframes don’t work with service worker caching. Chord charts are .docx and .pdf documents hosted on Google Drive (example) and rendered via iframe Service worker cache doesn’t work here because iframes start a new browsing context separate from your service worker.
- Search and filtering. My guitar chord site lets users search for chord charts by name, artist, or lyrics, and lets users filter by newest or by artist. How can we do this while offline? Service worker cache is insufficient here.
- HTML templates reused across URLs. My site is a single page app (SPA), where an HTML template (say, ChordDetails.html) is reused across many URLs (/chords/1, /chords/2, etc.) How can we tell service worker to use a single cached resource across different URLs?
These are the challenges I encountered. I solved them (mostly!), and that’s what this post is about. If you’re interested in building offline-capable web apps, you’ll learn something from this post.
The Goal
Since there are thousands of chord charts — several hundred MB worth of data — I don’t want to cache everything all at once.
Rather, my goal is to make the web app available offline by caching all static assets, then cache any chord charts viewed while online.
Put it another way, any chord charts viewed while online becomes available offline.
Making the web app load offline
This is the easy part. You add a service worker to your site, and configure your service worker to cache HTML, JS, CSS, web fonts, and other static assets.
Most “make your PWA offline-capable” articles on the web cover this — but only this.
However, even this “easy” part is fraught with gotchas. Cache invalidation? Cache expiration? Cache warming? Cache first or network first? Offline fallback? Revision-based URLs? etc.
Having implemented such service workers by hand in the past, I now recommend never doing that. 😂 Instead, use Google’s Workbox recipes in your service worker to handle all this for you.
Workbox recipes are small snippets of code that do common offline- and cache-related behaviors.
For example, here’s the static resource cache recipe:
import {staticResourceCache} from 'workbox-recipes';
staticResourceCache();What does staticResourceCache() do? It tells your service worker to respond to requests for static resources (CSS, JS, fonts, etc.), with a stale-while-revalidate caching strategy so those assets can be quickly served from the cache and be silently updated in the background. This means users get an instantaneous response from the cache. Meanwhile, the cached resource is refreshed in the background. Combine this with versioned resources (e.g. /scrips/main-hash123xyz.js) generated by Webpack, Rollup, or other build system, and you’ve got an automatic cache invalidation handled for you.
Workbox has a recipe for images (cache-first stategy with built-in expiration and cache pruning), a recipe for HTML pages (network-first with slow load time fallback), and more.
I use Workbox recipes in my service worker, and this makes my site work offline:
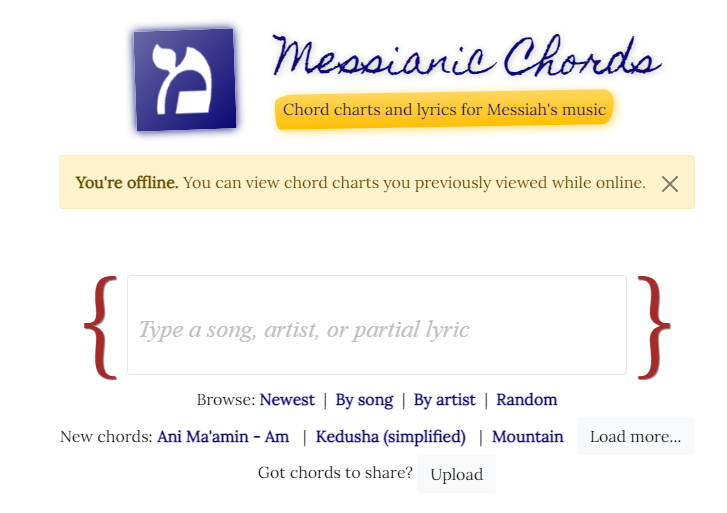
However, if we stopped there, you’ll notice that viewing a chord chart still fails:
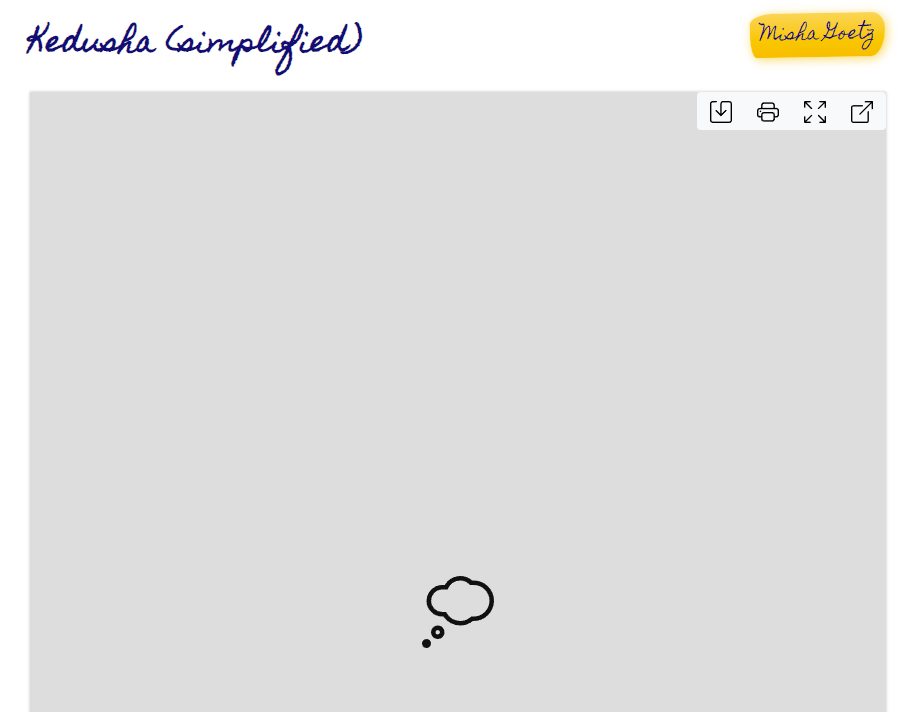
Well, crap.
We used Google Workbox and setup some recipes – shouldn’t the whole app work offline? Why is loading a chord chart failing?
iframes and service workers
The thousands of chord charts on MessianicChords are authored in .docx and .pdf format. There’s a reason for that: chord charts have special formatting (specifically, careful whitespacing) that needs to be preserved. Otherwise, you get a G chord playing over the wrong word, and now you’ve messed up your song:

Plus, the dozens of folks who contributed chord sheets to this prefer using these formats. 🤷♂️
Maybe in the future we migrate all of them to plain text/HTML; that would make them much easier to support offline. But for now, they use .docx and .pdf.
How do you display .docx and .pdf files on the web without using plugins or extensions?
With Google Docs iframes.
Google Docs does crazy work to render these on the web, no plugins required. (Under the hood, they’re converting these complex docs into raw HTML + CSS while meticulously preserving the formatting.)
So, MessianicChords embeds an iframe to load the .docx or .pdf in Google Docs.
What does that have to do with offline PWAs?
Your service worker can’t cache stuff from iframe loads. Viewing a chord chart on MessianicChords loads an iframe to a chord chart in Google Docs, but the request to this Google Docs URL isn’t cached by our service worker.
Why?
By design, iframes start a new browsing context. That means the service worker on MessianicChords doesn’t (and cannot) control the fetch requests the iframe makes to Google Docs.
End result is, my guitar chords site can’t load chord charts while offline. 😔
There is no magical way around this; it’s a deliberate limitation (feature?) of the web platform.
I considered some wild ideas to work around this. Could I statically cache the HTML and resources of the iframe and send it back with the chord chart from my own server? No, turns out Google Docs won’t work if not served from docs.google.com. This and other wild ideas I tried.
I finally settled on something of a low-tech solution: screenshots.
I created a service that would load the Google Doc in the browser, take a screenshot of that, and send that screenshot back with the chord chart. (Thanks, Puppeteer!)
When you view the chord chart, we load and cache the screenshot of the doc. When you’re offline, we render the cached screenshot instead.
It works pretty good! Here’s online and offline for comparison:

Not bad!
This approach does lose some fidelity: the user can’t select and copy text from the offline cached image, for example. However, the main goal of offline viewing is achieved.
Searching, filtering, and other dynamic functionality
We now have a web app that loads offline (thanks to service worker + Google Workbox recipes). And we can even view chord charts offline, thanks to caching screenshots of the docs.
If we stopped here, we’d unfortunately be missing some things. Specifically:
Search:

Filtering:
Making this sort of dynamic functionality work offline required additional work.
For search, we need to be able to search artists, song names, and lyrics. While we’re storing request/response for chord charts in the service worker cache, this is insufficient for our needs.
Why insufficient? Well, looking things up in the service worker cache typically requires sending in a request or URL from which the response is returned. But in the case of search, we have no URL or request; we’re just looking for data.
While theoretically I could fetch all chord charts from the cache, it felt like using the wrong tool for the job.
I briefly considered using the cheap and simple localStorage. But given my requirements of potentially thousands of chord charts, it too felt like the wrong tool. I also remembered localStorage has some performance issues and is intended for a few, small items, not the kind of stuff I’m storing.
If service worker cache and localStorage are both out, what’s our remaining options?
This is a full-blown indexed database built into the web platform with a many-readers-one-writer model. Its API is, like service worker, rather low-level. But it’s built for storing large(r) items and accessing them in a performant way. The right tool for this job.
I set out on implementing an IndexedDB-backed cache for chord charts. The finished product is chord-cache.ts: about 300 lines of code implementing various functionality of MessianicChords: searching, filtering, sorting chord charts.
Once implemented, I set out to make all my pages offline-aware
- The home page with search box would be updated to search the cache if we’re offline, or send an search request to the API if we’re online
- The artists page would be updated to query the cache if we’re offline, or query the API if we’re online
- …and so on
Except this is quite redundant. I realized, “Why am I coding this up for every page? Can we hide this behind a service?”
Good old object-oriented programming to the rescue. Since all API requests were made through my chord-service.ts, I changed that class’s behavior to be cache-aware and offline-aware. The following diagram explains the change:
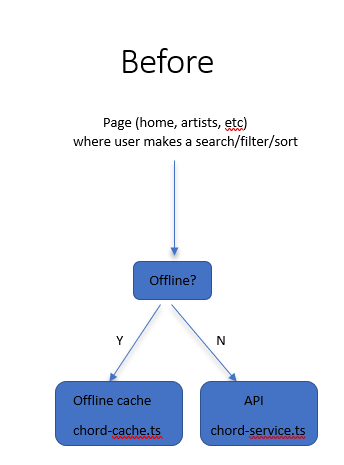
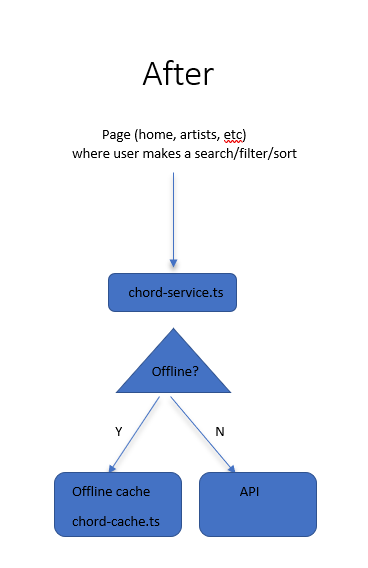
Sorry for the poor man’s diagram, but you get the picture. I made chord-service.ts call a ChordBackend interface. That interface has 2 implementations: one that hits our IndexedDB cache and another that hits our API. The former is used when we’re offline, the latter when we’re online.
This way, we don’t have to update any of our pages. The pages just talk to chord-service.ts like usual. Yay for polymorphism.
This means that only chord-service.ts needs to know when we’re offline. How does that work?
navigator.onLine and other lies
My first thought would be to use the built-in navigator.onLine API. There’s even an online/offline events paired with it to be notified when your online status changes. Perfect!
Except, these don’t really work in practice.
The thing is, “are you online?” isn’t a super easy question to answer. What I found was if my phone had zero bars out in podunk rural Iowa, I wasn’t really online, but navigator.onLine reported true. Gah!
I also saw weird things when testing offline via browser dev tools. I hit F12 -> Network -> Offline. Surely that would put us in offline mode, yes? Nope. Sometimes (not always?) navigator.onLine returned a false positive.
Even putting my iPhone in airplane mode was no guarantee navigator.onLine would give me a correct result. 😔
The documentation for navigator.onLine warns you about some of this:
In Chrome and Safari, if the browser is not able to connect to a local area network (LAN) or a router, it is offline; all other conditions return true. So while you can assume that the browser is offline when it returns a false value, you cannot assume that a true value necessarily means that the browser can access the internet. You could be getting false positives, such as in cases where the computer is running a virtualization software that has virtual ethernet adapters that are always “connected.” Therefore, if you really want to determine the online status of the browser, you should develop additional means for checking.
In Firefox and Internet Explorer, switching the browser to offline mode sends a false value. Until Firefox 41, all other conditions return a true value; testing actual behavior on Nightly 68 on Windows shows that it only looks for LAN connection like Chrome and Safari giving false positives.
MDN for navigator.onLine
“You should develop additional means for checking [online status].” 🙄
Yeah, that’s kinda what I had to do. I built online-detector.ts which basically just makes a no-op call to my API. If it fails, we’re offline.
Do I need to keep this offline status up-to-date?
Nah. For my purposes, we detect once and go from there. You need to reload the app to see a different offline status. That works for me. But if you need something better, you could periodically hit your API and fire an event as needed.
Pseudo full-text search with IndexedDB
The last challenge I encountered was full-text search. Now that we have our chord-cache.ts which caches chord charts, I could fetch them by name. But the name had to be exact.
Searching for “King” would not match the chord chart, “He is King“. That’s because of the way IndexedDB works. When querying an index, you can query by range or by exact value.
Query by range doesn’t work for my purposes. I could match everything up to “King” or everything after “King”, but not sentences that contain “King”.
Additionally, queries are case-sensitive by default.
To compensate for this, I created some additional indexes that stored all the words in the song title. “He is King” would store “he” and “king”. Kind of a poor man’s case-insensitive full-text search.
When the user queries for “King”, I convert it to lower case, then asynchronously query all my indexes for “king”. I feed all the results into a Set to remove duplicate results. Bingo, we have working(ish) offline search.’
HTML template reuse
When I viewed my service worker cache (F12 -> Application -> Cache Storage), I noticed an oddity: every chord chart route (e.g. https://messianicchords.com/ChordSheets/5697) had cached the same HTML template.
That’s because as a Single Page Application (SPA), we use an HTML template for all chord chart detail pages, asynchronously loading in the actual chord chart details.
Not a huge deal, but this means that if I cache 1000 chord charts, I’ll have the exact same HTML template in the service worker cache for each one. Wasteful.
Is there a way to tell our service worker cache, “Hey, if you come across /chords/123, use the same cached result from /chords/678”?
It turns out that yes, this is possible and is quite easy with Google Workbox custom plugins. Specifically, you can pass a function to Google Workbox’s various recipes to tell it cache keys to use. This lets me use the same cache key for all my chord chart details:
// Page cache recipe: https://developers.google.com/web/tools/workbox/modules/workbox-recipes#page_cache
pageCache({
plugins: [{
// We want to override cache key for
// - Artist page: /artist/Joe%20Artist
// - Chord details page: /ChordSheets/2630
// Reason is, these pages are the same HTML, just different behavior.
cacheKeyWillBeUsed: async function({request}) {
const isArtistPage = !!request.url.match(/\/artist\/[^\/]+$/);
if (isArtistPage) {
return new URL(request.url).origin + "/artist/_";
}
const chordDetailsRegex = new RegExp(/\/ChordSheets\/[\w|\d|-]+$/, "i");
const isChordDetailsPage = !!request.url.match(chordDetailsRegex);
if (isChordDetailsPage) {
return new URL(request.url).origin + "/ChordSheets/_"
}
return request.url;
}
}]
});Here we’re using the Google Workbox pageCache recipe, which hits the network and falls back to the cache if the network is too slow to respond.
We pass a custom plugin (really, just a function) to the recipe. It defines a cacheKeyWillBeUsed function, which Workbox uses to determine cache key. In it, I say, “If we’re navigating to chord details page, just use “ChordSheets/_” as the cache key.”
I do the same for artist page, for the same reason.
End result is, we avoid hundreds or thousands of duplicates for chord details and artist pages.
Summary
It’s possible to build great offline web apps. For most apps, service worker will suffice.
For my purposes, I needed to go further: adding an IndexedDB for my web app to enable full offline support for dynamic functionality like searching, filtering, and sorting.
iframes pose a difficulty for making your app available offline, as they start a new browsing context unintercepted by your service worker. If you own the domain you’re iframing, you can still make it work. For apps like mine that iframe content on domains I don’t own (docs.google.com in my case), I had to workaround the issue by creating screenshots of documents and loading those while offline.
My app doesn’t let users create or update data, so I didn’t have to manage this while offline. But the web platform can handle that, too, via BackgroundSync.
Bottom line: making a PWA offline is entirely possible. I think it’s amazing I can write software that works online and offline whether on iOS, Android, Windows, Mac, and VR/AR devices, using just a single codebase built on web standards.













 You don’t need to drink $15 Frappamochachino Grandes to design elegant UIs.
You don’t need to drink $15 Frappamochachino Grandes to design elegant UIs.






