levelsio on X wrote a provocative tweet yesterday on the future of websites:
Sure but realistically websites are probably a thing of the past in a few years
Everyone will just use whatever interactive calculator their AI chat app spins up for them, or it will just answer whatever calculation question they have
I work on the Microsoft Store and I’m invested in web platform standards. I think a lot about the future of apps and the web.
Will all that I know and love and work on soon be wiped out and replaced by the new AI thing? ☠️
In the future, why use websites? Just use AI to answer questions.
In the future, why use apps? Just use AI to open your garage door, listen to that podcast, translate that sentence, make a video call, summarize latest posts from the creators you follow.
AI becomes the everything app.
This is a pretty hot take. Yet, there might be some truth here as I examine my own tech usage and notice trends among family and friends:
I’m using search engines less. Instead of searching and sifting through links, I just ask an AI chatbot and get a direct answer. I’ll fallback to search engines only if I don’t trust the AI’s answer.
I’m using websites less. Why browse StackOverflow when I can just ask AI my question?
I want to use apps less. Instead of downloading, installing, and launching my garage door opener app, I just want to tell my garage door to open. Today that requires an app and/or a custom piece of hardware: a garage door opener! 😅. But it doesn’t need to include either of those things. I don’t want to use a custom piece of hardware or a custom app. I just want to tell my garage door to open. AI can do this in the future.
I’m already using AI for things previously only apps and websites did. For example, I’m learning the Hebrew language, and instead of using Google Translate on the web or the app on my phone, I just ask AI to translate or clarify terms and phrases. I’m using AI to help me write software, no longer relying on search engines, API docs, blogs, e-books, or tutorials. I’m using AI to give me dinner ideas and recipes when cooking for my family.
Using websites less
I suspect the trend to use search engines less is a strong, broad trend that will be widely adopted as years go by. Older people will still use search engines, but young people who haven’t been trained in the old ways will just use the easiest path to find information. From my vantage point, that looks to be AI chat bots.
Chat bots are easier to use than search engines.
With search engines, you type a query, get some ads, hunt and peck through the results, with each result opening a new context.
With chat bots, you type your query, get zero ads (for now), and get a direct answer to your question. It is a step towards the Star Trek future of communicating with computers in natural language.
If search engine use declines, websites will follow.
Why post on websites when no one will find you? Already, the web has become a wild west of malware, crypto scams, ad farms, content spam, SEO link boosters. The number of genuinely useful sites are decreasing because the eyeballs aren’t there; they’ve migrated to social media. Few people will read this post on the open web because everyone’s spending most of their time on social media and video shorts. (I’m guilty of this too.)
I’m noticing this trend in younger people. My kids don’t understand what a web browser is. They use just use social media apps, games, and increasingly AI.
This trend will accelerate as search engine traffic declines. There will be increasingly fewer reasons to post content to websites when the eyeballs are elsewhere.
This is a bit of a sad state, but seems to me a likely outcome. The web is the single repository of all human knowledge, but AI has already consumed it and can regurgitate it in nice, succinct answers in your AI chat bot.
Using apps less
The mobile platform shift resulted in people using apps more.
Apps are (theoretically) different from websites, in that they give you privileged access to your device hardware. My watch has an app that monitors my heartrate. My phone has an app that can made video calls.
The mobile platform shift resulted in apps becoming more important than websites.
The AI platform shift will result in chatbots becoming more important than apps.
And really, chatbots is not the right mental model; it’s too limited. Future use of AI won’t just be chat. AI agents could generate apps on the fly, creating UI to do whatever task you need. Some apps, like home security apps, will work with text or UI created on the fly: you could ask your AI if your frontdoor is locked (chat) or you could view your home security camera (UI created on the fly for you with video feed and playback controls).
What would it take to completely replace apps and websites?
I don’t think AI will completely replace apps, just as mobile apps didn’t completely replace websites.
But with this platform shift, there will be fewer reasons to build apps and websites.
A likely future direction for software development will be AI connectors. If you build home security systems, you’ll build connectors (MCP servers?) that will securely allow AIs to control a user’s home security system. If you build a podcast platform, you’ll build connectors that allow AI agents to browse and play podcasts. If you build email or chat, you’ll build connectors that allow AI to chat with a user’s contacts.
This trend will be resisted by companies and platforms for economic reasons. Social media companies won’t want to build connectors for AI agents because they need you to use their website/app so they can show you ads. The home security company won’t want to build AI connectors for your home security system, because the want you to use their app so they can upsell you on new home security devices.
The economic answer for this, then, is some sort of contract between the AI and the connector, where the connector requires the AI to display ads. Facebook, X, TikTok and others would build AI connectors if the contract for the connector said, “Any time you interact with our service, you must show one of our ads N% of the time.”
This would incentivize platforms to build connectors for AIs.
Websites should still exist.
I don’t want the web to disappear. AI wouldn’t exist without the web. The web still matters.
Especially for creators. The web allows creators to publish without approval, create without gatekeepers. It allows creators to own their own content. Websites matter, the web still matters.
But will users see it? In a world where human interaction with computers is mostly or even entirely via AI agents, it’s not clear to me how eyeballs will get on that content. Your grandchildren will talk to AIs, not browse the web. Your greatgrandchildren will use AI agents to do the thing, they won’t use apps.
It seems, then, there’s a need for a creator -> AI consumption pipeline. Maybe that’s still the web: the AI will continuously crawl the web for new content.
Today I experienced something I will remember for the rest of my software career.
It’s GitHub’s new Assign bug to Copilot feature. It feels like futuristic magic. It lets you assign opened issues on your GitHub repo to an AI agent to fix them:
Today, I tried it on a real project at work: Microsoft’s PWABuilder repo. We have about 140 opened issues in our backlog, many of them are due to accessibility issues.
I’m a developer and I enjoy writing code. But fixing accessibility bugs isn’t exactly exciting work. I had seen this assign-bug-to-Copilot demoed at Build a few weeks ago and was eager to try it out. This seemed like a good opportunity.
Copilot immediately created a draft PR, saying it’s forming a plan to fix the issue.
Within 30 minutes, Copilot pushed 2 commits, adding about 200 lines of CSS.
The code it wrote, by the way, fits into our architecture. We use standards-based Web Components in PWABuilder, and we use CSS media queries to define different layouts for the UI. Copilot’s PR created a new media query helper for extra small screens (< 320px width, effective size at 400% zoom) and updated our pages to use that.
Copilot filled out the PR’s description with a detailed list of the changes it made and why. It then requested my review.
The code looked good. But I checked out the branch it created and ran it locally. Woops, there’s still a problem with the app header. I told Copilot about it in the PR:
Within 30 seconds, Copilot had a fix ready:
I tried out the updated code:
So, that went really well.
But, I’ve got like dozens of accessibility bugs, and over a hundred issues opened in the backlog. How about I just assign a bunch of them to Copilot? I told my team,
I assigned a bunch of opened issues to Copilot. Within minutes, I had dozens of PRs opened, with Copilot showing the progress of each one:
Copilot is a great multitasker. 🙂 He is working on dozens of PRs simultaneously.
Within about 30 minutes, I’ve got 13 PRs ready for review.
Magic. I’m living in the future.
I’m not naive in saying that. I heavily use Copilot Agent in VSCode in my day-to-day work. I’ve watched — with slight horror and great amusement — AI agents create software out of thin air via vibe coding. I’m aware of what’s possible.
Yet, having AI do all the work on a real project, on a real bug, without much intervention from humans? And the AI agent working on many bugs and PRs concurrently? Well, that feels magical.
It’s something I’ll remember for the rest of my career. A new era. Is it a bell toll for white collar tech jobs or a boon for productivity? This remains to be seen.
Web apps get a bad rap. They are sometimes slower than their native counterparts. They feel out-of-place if their UI varies greatly from the native platform.
But web apps also have things native apps are missing. Here are some of them.
I can find text. In any web app, I can press CTRL+F to find text on the page. I use this dozens of times daily. When I’m using a native app, I have to resort to scanning text manually.
I can login with one click. I use a password manager to keep track of my logins across thousands of sites. When I have to use a native app like Disney+ and I need to login, I don’t know my password, and password managers don’t generally work on native (desktop especially, but sometimes also on mobile). I have to launch my browser, launch my password manager in the browser and copy/paste my credentials.
I can select text. I often use text selection as a reading aid. I also use it to grab snippets of text, repost a quote, share it. With native apps, I can’t do this.
I can fill out forms automatically. Does that app need your name, address, phone, email, and more? With native apps, I have to type all that. With web apps, my browser or password manager can do it automatically for me.
I can share app content. You see something in the app and you want to share it. On the web, you can just send the link to friends. (Or even better, link to individual elements on the page, or even link to a section of text.) If it’s an image or video, you can right-click and grab the link to it, save it to disk, or send it to another app. But if it’s a native app, I can’t do those things.
I can pay for things without typing my credit card details. On the web when I go to pay for something, the browser or password manager can fill out your credit card details with a single click. On native, I’ll have to find my card and physically type the name, type of card, card number, expiration date, CVV.
I can open another part of the app without leaving my context. You’re deep in an app. You maybe browsed for movies, navigated to the 8th section, horizontally scrolled until you found the one you’re looking for. Before you hit play, you want to quickly check the name of that other movie you watched. You could click Recently Watched…but then you’ll lose your current context and have to do it all over again. Unless you’re a web app, then you can just Ctrl+click/middle click to open Recently Watched in a new tab while preserving your context in the current tab. Native apps don’t do this, forcing you to lose you context.
I can get to the content quickly. For all the talk about native performance, native apps often load slower than web apps. One reason for that may be because inefficiencies of higher abstractions in native development. But the web has something native does not have: multiple billion dollar companies competing to make it fast. Apple, Google, Microsoft, Mozilla, Samsung and others are investing heavily in making the web fast. The browser wars are survival of the fittest, and the resulting competition benefits end users. The same cannot be said of any native app framework, desktop or mobile.
I can block ads. For years I’ve used the Twitter web app both on mobile and desktop; just go to Twitter.com. The Twitter web app has some problems. Once I thought I’d try the Twitter native app. Oooh, the scrolling seemed smoother. Oooh, I didn’t have the weird bug where I open an image, pinch-to-zoom, causing accidental refresh of my feed. Nice. Except…ads. Ads everywhere. I didn’t realize I was missing them because I had be using the web app, which lets me block ads. Increasingly, developers will publish a native version of their app to let them push more ads in front of more eyeballs. With native apps, I can’t block ads or tracking scripts.
I can scale text and media. Text too small? Need to zoom in on that image? Ctrl + Plus. Web apps let me do this, native apps don’t. Closest I can get on native is the OS-level zoom (e.g. Win+Plus) to get a closeup on the area near the cursor, which doesn’t often suit the task at hand.
I can keep using the app even if its busy. Or, “dog.exe has stopped responding”. Web apps have simpler threading models than native apps and this makes for UIs that tend to be responsive. On the web, when you need to do blocking work like network calls, it’s usually async by default (e.g. fetch(…), import(…), etc.). No need to schedule completion work on another thread; that’s built in. In native land, many developers just do the work on the UI thread, leading to unresponsive apps. Still others will try to coordinate their own threading, which can result in deadlocks, race conditions, or memory errors. While these are possible on the web, they’re much bigger footguns in the native world.
I can keep working even if something goes wrong. An unhandled exception occurred when you clicked a button? The native app may just crash, losing your work in the process. “Better die and start over than continue in an unknown state”, is the idealistic advice. On the web, that unhandled exception shows up in the developer console, the web app just keeps running and your work is preserved. This is the pragmatic outlook baked into the web itself: even malformed HTML documents still render successfully.
These are a few off the top of my head. Add any more in the comments, I’ll add them to the post.
Spent the last 4 days making a PWA offline-capable.
Tricky, as it’s a viewer of cloud documents. (Guitar chord charts)
Workbox recipes, custom Workbox plugins, IndexDB to mirror backend API, pseudo full text search via IDB indexes, phew!
Learned a lot! Blog forthcoming.
— Judah Gabriel 🇮🇱 יהודה גבריאל (@JudahGabriel) June 15, 2022
You can build web apps (really, fancy websites) that work offline. When you build one of these things, you can put your device into airplane mode, open your browser and navigate to your URL, and it’ll just work. Pretty cool!
This is the promise of Progressive Web Apps (PWAs): you can build web apps that work like native apps, including ability to run offline.
I’ve built simple offline PWAs in the past, and things worked fairly well.
But this week I needed to do something trickier.
I run MessianicChords.com, a guitar chord chart site for Messianic Jewish music, and I needed to make it work offline. I would soon be traveling to a Messianic music festival where there’s little to no internet connection , and, as a guitar player myself, I wanted to bring up MessianicChords and access the chord charts even while offline.
So I figured, let’s make MessianicChords work entirely offline. Fun!
But this was trickier and a real test of the web platform’s offline capabilities:
Lots of content. My site has thousands of chord charts, totalling in the hundreds of MB. I can’t just cache everything all at once.
iframes don’t work with service worker caching. Chord charts are .docx and .pdf documents hosted on Google Drive (example) and rendered via iframe Service worker cache doesn’t work here because iframes start a new browsing context separate from your service worker.
Search and filtering. My guitar chord site lets users search for chord charts by name, artist, or lyrics, and lets users filter by newest or by artist. How can we do this while offline? Service worker cache is insufficient here.
HTML templates reused across URLs. My site is a single page app (SPA), where an HTML template (say, ChordDetails.html) is reused across many URLs (/chords/1, /chords/2, etc.) How can we tell service worker to use a single cached resource across different URLs?
These are the challenges I encountered. I solved them (mostly!), and that’s what this post is about. If you’re interested in building offline-capable web apps, you’ll learn something from this post.
The Goal
Since there are thousands of chord charts — several hundred MB worth of data — I don’t want to cache everything all at once.
Rather, my goal is to make the web app available offline by caching all static assets, then cache any chord charts viewed while online.
Put it another way, any chord charts viewed while online becomes available offline.
Making the web app load offline
This is the easy part. You add a service worker to your site, and configure your service worker to cache HTML, JS, CSS, web fonts, and other static assets.
Most “make your PWA offline-capable” articles on the web cover this — but only this.
However, even this “easy” part is fraught with gotchas. Cache invalidation? Cache expiration? Cache warming? Cache first or network first? Offline fallback? Revision-based URLs? etc.
Having implemented such service workers by hand in the past, I now recommend never doing that. 😂 Instead, use Google’s Workbox recipes in your service worker to handle all this for you.
Workbox recipes are small snippets of code that do common offline- and cache-related behaviors.
import {staticResourceCache} from 'workbox-recipes';
staticResourceCache();
What does staticResourceCache() do? It tells your service worker to respond to requests for static resources (CSS, JS, fonts, etc.), with a stale-while-revalidate caching strategy so those assets can be quickly served from the cache and be silently updated in the background. This means users get an instantaneous response from the cache. Meanwhile, the cached resource is refreshed in the background. Combine this with versioned resources (e.g. /scrips/main-hash123xyz.js) generated by Webpack, Rollup, or other build system, and you’ve got an automatic cache invalidation handled for you.
Workbox has a recipe for images (cache-first stategy with built-in expiration and cache pruning), a recipe for HTML pages (network-first with slow load time fallback), and more.
I use Workbox recipes in my service worker, and this makes my site work offline:
However, if we stopped there, you’ll notice that viewing a chord chart still fails:
Chord chart fails to load while offline
Well, crap.
We used Google Workbox and setup some recipes – shouldn’t the whole app work offline? Why is loading a chord chart failing?
iframes and service workers
The thousands of chord charts on MessianicChords are authored in .docx and .pdf format. There’s a reason for that: chord charts have special formatting (specifically, careful whitespacing) that needs to be preserved. Otherwise, you get a G chord playing over the wrong word, and now you’ve messed up your song:
Plus, the dozens of folks who contributed chord sheets to this prefer using these formats. 🤷♂️
Maybe in the future we migrate all of them to plain text/HTML; that would make them much easier to support offline. But for now, they use .docx and .pdf.
How do you display .docx and .pdf files on the web without using plugins or extensions?
With Google Docs iframes.
Google Docs does crazy work to render these on the web, no plugins required. (Under the hood, they’re converting these complex docs into raw HTML + CSS while meticulously preserving the formatting.)
So, MessianicChords embeds an iframe to load the .docx or .pdf in Google Docs.
What does that have to do with offline PWAs?
Your service worker can’t cache stuff from iframe loads. Viewing a chord chart on MessianicChords loads an iframe to a chord chart in Google Docs, but the request to this Google Docs URL isn’t cached by our service worker.
Why?
By design, iframes start a new browsing context. That means the service worker on MessianicChords doesn’t (and cannot) control the fetch requests the iframe makes to Google Docs.
End result is, my guitar chords site can’t load chord charts while offline. 😔
There is no magical way around this; it’s a deliberate limitation (feature?) of the web platform.
I considered some wild ideas to work around this. Could I statically cache the HTML and resources of the iframe and send it back with the chord chart from my own server? No, turns out Google Docs won’t work if not served from docs.google.com. This and other wild ideas I tried.
I finally settled on something of a low-tech solution: screenshots.
I created a service that would load the Google Doc in the browser, take a screenshot of that, and send that screenshot back with the chord chart. (Thanks, Puppeteer!)
When you view the chord chart, we load and cache the screenshot of the doc. When you’re offline, we render the cached screenshot instead.
It works pretty good! Here’s online and offline for comparison:
Not bad!
This approach does lose some fidelity: the user can’t select and copy text from the offline cached image, for example. However, the main goal of offline viewing is achieved.
Searching, filtering, and other dynamic functionality
We now have a web app that loads offline (thanks to service worker + Google Workbox recipes). And we can even view chord charts offline, thanks to caching screenshots of the docs.
If we stopped here, we’d unfortunately be missing some things. Specifically:
Search:
Searching “blessing” on MessianicChords returns chord charts with “blessing” in the title, artist, or lyrics. How can we make this work offline?
Filtering:
MessianicChords lets users filter chord charts by artist or song name, or order by recent. How can we make this work offline?
Making this sort of dynamic functionality work offline required additional work.
For search, we need to be able to search artists, song names, and lyrics. While we’re storing request/response for chord charts in the service worker cache, this is insufficient for our needs.
Why insufficient? Well, looking things up in the service worker cache typically requires sending in a request or URL from which the response is returned. But in the case of search, we have no URL or request; we’re just looking for data.
While theoretically I could fetch all chord charts from the cache, it felt like using the wrong tool for the job.
I briefly considered using the cheap and simple localStorage. But given my requirements of potentially thousands of chord charts, it too felt like the wrong tool. I also remembered localStorage has some performance issues and is intended for a few, small items, not the kind of stuff I’m storing.
If service worker cache and localStorage are both out, what’s our remaining options?
This is a full-blown indexed database built into the web platform with a many-readers-one-writer model. Its API is, like service worker, rather low-level. But it’s built for storing large(r) items and accessing them in a performant way. The right tool for this job.
I set out on implementing an IndexedDB-backed cache for chord charts. The finished product is chord-cache.ts: about 300 lines of code implementing various functionality of MessianicChords: searching, filtering, sorting chord charts.
Once implemented, I set out to make all my pages offline-aware
The home page with search box would be updated to search the cache if we’re offline, or send an search request to the API if we’re online
The artists page would be updated to query the cache if we’re offline, or query the API if we’re online
…and so on
Except this is quite redundant. I realized, “Why am I coding this up for every page? Can we hide this behind a service?”
Good old object-oriented programming to the rescue. Since all API requests were made through my chord-service.ts, I changed that class’s behavior to be cache-aware and offline-aware. The following diagram explains the change:
Sorry for the poor man’s diagram, but you get the picture. I made chord-service.ts call a ChordBackend interface. That interface has 2 implementations: one that hits our IndexedDB cache and another that hits our API. The former is used when we’re offline, the latter when we’re online.
This way, we don’t have to update any of our pages. The pages just talk to chord-service.ts like usual. Yay for polymorphism.
This means that only chord-service.ts needs to know when we’re offline. How does that work?
navigator.onLine and other lies
My first thought would be to use the built-in navigator.onLine API. There’s even an online/offline events paired with it to be notified when your online status changes. Perfect!
Except, these don’t really work in practice.
The thing is, “are you online?” isn’t a super easy question to answer. What I found was if my phone had zero bars out in podunk rural Iowa, I wasn’t really online, but navigator.onLine reported true. Gah!
I also saw weird things when testing offline via browser dev tools. I hit F12 -> Network -> Offline. Surely that would put us in offline mode, yes? Nope. Sometimes (not always?) navigator.onLine returned a false positive.
Even putting my iPhone in airplane mode was no guarantee navigator.onLine would give me a correct result. 😔
The documentation for navigator.onLine warns you about some of this:
In Chrome and Safari, if the browser is not able to connect to a local area network (LAN) or a router, it is offline; all other conditions return true. So while you can assume that the browser is offline when it returns a false value, you cannot assume that a true value necessarily means that the browser can access the internet. You could be getting false positives, such as in cases where the computer is running a virtualization software that has virtual ethernet adapters that are always “connected.” Therefore, if you really want to determine the online status of the browser, you should develop additional means for checking.
In Firefox and Internet Explorer, switching the browser to offline mode sends a false value. Until Firefox 41, all other conditions return a true value; testing actual behavior on Nightly 68 on Windows shows that it only looks for LAN connection like Chrome and Safari giving false positives.
“You should develop additional means for checking [online status].” 🙄
Yeah, that’s kinda what I had to do. I built online-detector.ts which basically just makes a no-op call to my API. If it fails, we’re offline.
Do I need to keep this offline status up-to-date?
Nah. For my purposes, we detect once and go from there. You need to reload the app to see a different offline status. That works for me. But if you need something better, you could periodically hit your API and fire an event as needed.
Pseudo full-text search with IndexedDB
The last challenge I encountered was full-text search. Now that we have our chord-cache.ts which caches chord charts, I could fetch them by name. But the name had to be exact.
Searching for “King” would not match the chord chart, “He is King“. That’s because of the way IndexedDB works. When querying an index, you can query by range or by exact value.
Query by range doesn’t work for my purposes. I could match everything up to “King” or everything after “King”, but not sentences that contain “King”.
Additionally, queries are case-sensitive by default.
To compensate for this, I created some additional indexes that stored all the words in the song title. “He is King” would store “he” and “king”. Kind of a poor man’s case-insensitive full-text search.
When the user queries for “King”, I convert it to lower case, then asynchronously query all my indexes for “king”. I feed all the results into a Set to remove duplicate results. Bingo, we have working(ish) offline search.’
HTML template reuse
When I viewed my service worker cache (F12 -> Application -> Cache Storage), I noticed an oddity: every chord chart route (e.g. https://messianicchords.com/ChordSheets/5697) had cached the same HTML template.
That’s because as a Single Page Application (SPA), we use an HTML template for all chord chart detail pages, asynchronously loading in the actual chord chart details.
Not a huge deal, but this means that if I cache 1000 chord charts, I’ll have the exact same HTML template in the service worker cache for each one. Wasteful.
Is there a way to tell our service worker cache, “Hey, if you come across /chords/123, use the same cached result from /chords/678”?
It turns out that yes, this is possible and is quite easy with Google Workbox custom plugins. Specifically, you can pass a function to Google Workbox’s various recipes to tell it cache keys to use. This lets me use the same cache key for all my chord chart details:
// Page cache recipe: https://developers.google.com/web/tools/workbox/modules/workbox-recipes#page_cache
pageCache({
plugins: [{
// We want to override cache key for
// - Artist page: /artist/Joe%20Artist
// - Chord details page: /ChordSheets/2630
// Reason is, these pages are the same HTML, just different behavior.
cacheKeyWillBeUsed: async function({request}) {
const isArtistPage = !!request.url.match(/\/artist\/[^\/]+$/);
if (isArtistPage) {
return new URL(request.url).origin + "/artist/_";
}
const chordDetailsRegex = new RegExp(/\/ChordSheets\/[\w|\d|-]+$/, "i");
const isChordDetailsPage = !!request.url.match(chordDetailsRegex);
if (isChordDetailsPage) {
return new URL(request.url).origin + "/ChordSheets/_"
}
return request.url;
}
}]
});
Here we’re using the Google Workbox pageCache recipe, which hits the network and falls back to the cache if the network is too slow to respond.
We pass a custom plugin (really, just a function) to the recipe. It defines a cacheKeyWillBeUsed function, which Workbox uses to determine cache key. In it, I say, “If we’re navigating to chord details page, just use “ChordSheets/_” as the cache key.”
I do the same for artist page, for the same reason.
End result is, we avoid hundreds or thousands of duplicates for chord details and artist pages.
Summary
It’s possible to build great offline web apps. For most apps, service worker will suffice.
For my purposes, I needed to go further: adding an IndexedDB for my web app to enable full offline support for dynamic functionality like searching, filtering, and sorting.
iframes pose a difficulty for making your app available offline, as they start a new browsing context unintercepted by your service worker. If you own the domain you’re iframing, you can still make it work. For apps like mine that iframe content on domains I don’t own (docs.google.com in my case), I had to workaround the issue by creating screenshots of documents and loading those while offline.
My app doesn’t let users create or update data, so I didn’t have to manage this while offline. But the web platform can handle that, too, via BackgroundSync.
Bottom line: making a PWA offline is entirely possible. I think it’s amazing I can write software that works online and offline whether on iOS, Android, Windows, Mac, and VR/AR devices, using just a single codebase built on web standards.
Spin up a RavenDB database quickly and cheaply. Create a highly-available database cluster in minutes. Try out the all new RavenDB Cloud for free at cloud.ravendb.net.
RavenDB Cloud is a new database-as-a-service from the creators of RavenDB. No need to download any software, futz with port forwarding or virtual machine management: just visit cloud.ravendb.net and spin up a RavenDB instance.
RavenDB itself is a distributed database: while it can run as a single server, Raven is designed to work well in a cluster, multiple instances of your database that sync to each other and keep your app running even if a database server goes down. RavenDB Cloud builds on this and makes it super simple to spin up a database cluster to make your app more scalable and resilient.
In this article, I’ll walk you through both. We’ll start by spinning up a basic, single node instance in RavenDB Cloud. Then I’ll show you how to spin up a full cluster. All the while, we’ll be talking to our database from an ASP.NET Core web app. Let’s get started!
Spinning up a (free!) RavenDB Cloud instance
RavenDB Cloud offers a free instance. This is great for testing the waters and doing some dev hacking on Raven. I also use the free instance as my “local” database during development; it’s super easy to spin up an instance in RavenDB Cloud and point my locally running apps at. Let’s do that now.
You’ll register with your email address and then you’ll be asked what domain you’d like. This will be the URL through which you’ll access your databases. For this CodeProject article, I decided on a fitting name :
The next step is optional: billing information. If you’re just playing around with the free instance, you can click “skip billing information.” Now we’re presented with the final summary of our information. Click “Sign up” and we’re ready to roll:
Now we’re registered and we’ll receive our sign in link via email:
I’ve now got an email with a magic link that signs me in. Clicking that link takes me to my RavenDB Cloud dashboard:
Here we’ll create a new product: our free RavenDB Cloud instance.
You might wonder: what do we mean by “product” here – is it just a single database? A product here really means a cloud server(s) in which one or more databases reside. So, for example, our free instance can have multiple databases inside of it, as we’ll see shortly.
We’ll click “Add Product” and we’re asked what we want to create, with the default being the free instance:
If we change nothing on this screen, we’ll create a free instance, which is perfect for our initial setup.
Before we move on, notice we can create an instance either in Amazon’s or Microsoft’s cloud. We can also choose the region, for example, AWS Canada, or Azure West US:
We can also choose the tier: Free, Development, or Production. For our first example here, we’re going to go with the free instance.
It’s limited to a single node – no highly available cluster –10 GB of disk space, running on low-end hardware (2 vCPUs and 0.5 GB RAM). That’s fine for testing and for small projects; perfect for testing the waters. We’ll go ahead and choose the free instance and click Next.
Now we can specify the Display Name of the product; this is what we’ll see on our dashboard. Optionally, you can limit access to your database by IP range. Raven databases are secure by default using client certificates – we’ll talk about these more in a moment – so limiting access to an IP range isn’t strictly necessary, but adds an additional layer of security. For now, I’ll leave the IP range opened to the world.
We’ll click Next to see the summary of our RavenDB Cloud product, then click Create.
Once we click Create, I can see the free instance on my dashboard:
Here you can see our free instance spinning up in AWS, with a yellow “Creating” status. After a moment, it will finish spinning up and you’ll see the product go green in the Active state:
Congrats! You just spun up a free RavenDB Cloud instance.
We want to connect to this instance and create some databases. We can do that through code, but with RavenDB, we can also do it through the web using Raven’s built-in tooling, Raven Studio. You’ll notice the URLs section of the instance: that’s the URL that we can access our database server and create databases in.
But wait – isn’t that a security risk? If you try it right now in your browser, going to https://a.free.clistctrl.ravendb.cloud, you’ll be prompted for a security certificate. Where do you get the certificate? RavenDB Cloud generates one for you, and it’s available through the “Download Certificate” button:
Clicking “Download Certificate” will download a zip file containing a .pfx file – the certificate we need to access our database server:
(Yes, I really did pay for a registered copy of WinRAR)
You’ll see 2 .pfx files in there: one with a password, one without. You’re free to use either, but for our purposes, we’re going to use the one without a password. I’ll double-click free.clistctrl.client.certificate.pfx and click Next all the way through until I’m done; no special settings needed.
Once I’ve installed that certificate, I can now securely access my database using the URL listed in the dashboard:
Note: If you tried to access the URL before installing the certificate, you may run into an issue where your browser won’t prompt you for a certificate even after installing it. If that happens, simply restart your browser, or alternately, open the link in a private/incognito browser window.
Going to that URL in Chrome will prompt me to choose a certificate. I’ll choose the one we just installed, free.clistctrl. Hooray! We’re connected to our free RavenDB Cloud instance:
What we’re looking at here is RavenDB’s built-in tooling, Raven Studio. You can think of Raven Studio akin to e.g. SQL Management Studio: it’s where we can create databases, view data in our databases, execute queries, etc.
Our first step is going to be creating a database. I’m going to click Databases -> New database. I’m going to name it Outlaws, which we’ll use to store wonderful mythic outlaws of the wild west.
After clicking, we have a new database up and running in RavenDB Cloud – woohoo!
How does it look to connect to this database from, say, an ASP.NET Core web app? It’s pretty simple, actually. I’m going to do that now, just to show how simple it is.
While RavenDB has official clients for .NET, JVM, Go, Python, Node.js, and C++, I’m most familiar with C# and .NET, and I think Raven shines brightest on .NET Core. So, I’ve created a new ASP.NET Core web app in Visual Studio, then I add the RavenDB.Client NuGet package.
Inside our StartUp.cs, I initialize our connection to Raven:
That’s it! We can now store stuff in our database:
Likewise, we can query for our objects easily:
Saving and querying is a breeze – if you’re new to Raven, I encourage you to check out the awesome learning materials to help you get started.
One final note here: you can spin up multiple databases inside your RavenDB Cloud product. In this case, we’ve spun up a free instance and created a single Outlaws database inside it, but we can also can spin up other databases on this same free server as needed. Since the free tier supports 10GB disk space, we can spin up as many databases as can fit inside 10GB.
Spinning up a cluster in RavenDB Cloud
We just finished setting up a free instance in RavenDB Cloud, created a database, and connected to it, saved and queried some data.
All well and good.
But what happens when your database server goes down – does your app stop working? In our case, suppose AWS or Azure had a major outage, and our free instance goes offline. The result is that our app would stop working; it can’t reach the database.
RavenDB is, at its core, a distributed database: it’s designed to run multiple copies of your database in a cluster. A cluster is 3 or more nodes – database server instances – in which all the databases sync with each other. If one node goes down, the others still work, and your app will automatically switch to one of the online nodes. We call this transparent failover. When the node comes back online, all the changes that happened while it was offline get automatically synced to it.
A wonderful part of all this is you don’t have to do extra work to make this happen – you just setup your database as a cluster, and Raven takes care of the rest. The upside is your app is more resilient to failure: if one of your database nodes goes down, your app keeps working.
Let’s try that now using RavenDB Cloud.
We’ll go back to the RavenDB Cloud portal. We already have our CodeProjectFree product:
Let’s add a new product, we’ll call it CodeProjectCluster. I’ll click Add Product like before, but this time, we’re going to specify Production tier, which will setup our database in a 3 node cluster:
You’ll notice above we set Tier level to Production – this will setup our database in a cluster. We can tweak the CPU priority, cluster size, and storage size as needed; for this example we’ll leave these at the smallest sizes.
We’ll click next and set the instance names as before. Click finish, and we’re ready to roll: on our dashboard, we now see the cluster being created:
Notice that while our CodeProjectFree instance contains a single URL – there’s only 1 node – our new CodeProjectCluster contains 3 URLs, each one being a node in the cluster. The first node is node A, so its URL is a.cluster.clistctrl.ravendb.cloud, the second node is node B with a corresponding URL, and so on.
Once the cluster is finished creating, I’ll download and install the certificate as before:
Even though we have 3 nodes, we have a single certificate that will work for all 3 nodes. Once I’ve downloaded and installed it, I can click on any of the node URLs. Let’s try the 2nd node, Node B, which is at https://b.cluster.clistctrl.ravendb.cloud. That URL takes me to Raven Studio for Node B:
Let’s go ahead and create a new database on this node. As before, I’ll click Databases -> New Database, and we’ll call it OldWestHeroes:
Notice we now have a Replication factor of 3. This means our OldWestHeroes database will be replicated – copied and automatically synchronized – across all 3 nodes. Once we click Create, the database will be created and we’ll see it on the node:
But since we’re running in a cluster, this database will also automatically be created on the other nodes. Notice under the database name, we see Node B, Node C, and Node A; Raven Studio is telling us this database is up and ready on all our 3 nodes.
Click the Manage group button, and we can see a visual description of our cluster topology:
On the right, we can see all 3 nodes are all replicating to each other. (If any nodes were offline, we would see the node here as red with a broken connection.)
This visual tells us our database is working on all 3 nodes in our cluster. It also shows ongoing tasks, such as automatic backups, hanging off the nodes responsible for the task. You’ll notice that “Server Wide Backup” task is hanging off Node A – RavenDB Cloud creates this task for us automatically. Database backups are free for up to 1GB, and for $1/GB/month beyond that.
We’re looking at Node B right now, but since all 3 nodes in our cluster are up and running, we should see the database on any of the other nodes.
Yep! Our OldWestHeroes database has been automatically created on this node. And because these nodes are automatically synchronized, any changes we make to one node will show up automatically on the other nodes.
Let’s try that out too. Here on Node A, I’m going to click the OldWestHeroes database, then click New Document. I’ll create a new Cowboy document:
I’ll click save and our database now has a single Cowboy in it:
And because we’re in cluster, all the other nodes will now have this same document in it. Let’s head over to Node C, located at: https://c.cluster.clistctrl.ravendb.cloud:
Sure enough, our Cowboy document is there. I can edit this Cowboy and change his name, and of course those changes will be synced to all the other nodes.
How does that change our app code? Going back to our C# web app, does our code have to change?
Not much! The code is essentially the same as before, but instead of specifying a single URL, we specify the URLs of all the nodes in our cluster:
This one-time initialization code in our Startup.cs file is the only code that has to change. The rest of the app code doesn’t change; we can still write objects and query them as usual:
Ditto for querying:
The upside for our app is even if some of the nodes in our cluster goes down – say, for instance, if there’s an Azure outage – our app keeps working, transparently failing over to other nodes in the cluster. No extra code needed!
Summary
In this article, I’ve shown how to quickly spin up a free database in RavenDB Cloud. We showed how it’s secured with a certificate and how we can connect to it from a C# web app. It’s quick and easy and great for testing the waters.
We also looked at something more production-ready: spinning up a 3 node cluster in RavenDB Cloud. We looked at how databases in the cluster are automatically synced with all the nodes. Any changes in one node are automatically and quickly replicated to the other nodes. We also looked at the minimal (2 additional lines) code required to change our web app from our free single-node instance to our 3 node cluster.
Apps running against a cluster are more resilient in the face of failure: your app keeps running even if some of the nodes go down. Raven allows reading and writing to any of the nodes of the cluster, keeping your app running in the face of hardware failure or network issues.
RavenDB Cloud lets you spin up a single RavenDB instance or full production cluster quickly and easily in the cloud. I hope this article has helped you understand what it is and why you’d use it, and I hope you’ll give it try today: cloud.ravendb.net
Summary: How to use TypeScript async/await with AngularJS 1.x apps, compiling down to ES5 browsers.
With TypeScript 2.1+, you can start using the awesome new async/await functionality today, even if your users are running old browsers. TypeScript will compile it down to something all browsers can run.
I’m using Angular 1.x for many of my apps. I wanted to use the sexy new async/await functionality in my Angular code. I didn’t find any examples online how to do this, so I did some experimenting and figured it out.
For the uninitiated, async/await is a big improvement on writing clean async code:
Getting this to work with Angular is pretty simple, requiring only a single step.
1. Use $q for Promise
Since older browsers may not have a global Promise object, we need to drop in a polyfill. Fortunately, we can just use Angular’s $q object as the Promise, as it’s A+ compatible with the Promise standard.
This kills two birds with one stone: we now have a Promise polyfill, and when these promises resolve, the scope will automatically be applied.
2. You’re done! Sort of…
That’s actually enough to start using async/await against Promise-based code, such as ng.IPromise<T>:
Cool. We’re cooking with gas. Except…
Making it cleaner.
If you look at the transpiled javascript, you’ll see that TypeScript is generating 2 big helper functions at the top of every file that uses an async function:
Yikes! Sure, this is how the TypeScript compiler is working its magic: simulating async/await on old platforms going back to IE8 (and earlier?).
Love the magic, but hate the duplication; we’re generating this magic for every TS file that uses async functions. Ideally, we’d just generate the magic once, and have all our async functions reuse it.
We can do just that, explained in steps 3 and 4 below.
3. Use noEmitHelpers TS compiler flag
The TypeScript 2.1+ compiler supports the noEmitHelpers flag. This will isntruct TypeScript not to emit any of its helpers: not for async, not for generators, not for class inheritance, …nuttin’.
Let’s start with that. In my tsconfig.json file, I add the flag:
You can see we’ve set noEmitHelpers to true in line 8. Now if we compile our app, you’ll notice the transpiled UsersController.js (and your code files that use async functions) no longer has all the magic transpiler stuff. Instead, you’ll notice your async functions are compiled down to something like this:
Ok – that actually looks fairly clean. Except if you run it, you’ll get an error saying __awaiter is undefined. And that’s because we just told TypeScript to skip generating the __awaiter helper function.
Instead of having TypeScript compiler generate that in each file, we’re just going to define those magic helper functions once.
4. Use TsLib.js to define the magic helper functions once.
Microsoft maintains tslib, the runtime helpers library for TypeScript apps. It’s all contained in tslib.js, single small file (about 200 lines of JS) that defines all helper functions TypeScript can emit. I added this file to my project, and now all my async calls work again.
Alternately, you can tell the TypeScript compiler to do that for you using the importHelpers flag.
Summary: RavenDB opens up some new possibilities for working with view models: objects that contain pieces of data from other objects. With Raven, we can use .Include to simulate relational joins. But we can go beyond that for superior performance by exploiting Raven’s transformers, custom indexes, and even complex object storage.
Modern app developers often work with conglomerations of data cobbled together to display a UI page. For example, you’ve got a web app that displays tasty recipes, and on that page you also want to display the author of the recipe, a list of ingredients and how much of each ingredient. Maybe comments from users on that recipe, and more. We want pieces of data from different objects, and all that on a single UI page.
For tasks like this, we turn to view models. A view model is a single object that contains pieces of data from other objects. It contains just enough information to display a particular UI page.
In relational databases, the common way to create view models is to utilize multiple JOIN statements to piece together disparate data to compose a view model.
But with RavenDB, we’re given new tools which enable us to work with view models more efficiently. For example, since we’re able to store complex objects, even full object graphs, there’s less need to piece together data from different objects. This opens up some options for efficiently creating and even storing view models. Raven also gives us some new tools like Transformers that make working with view models a joy.
In this article, we’ll look at a different ways to work with view models in RavenDB. I’ll also give some practical advice on when to use each approach.
The UI
We’re building a web app that displays tasty recipes to hungry end users. In this article, we’ll be building a view model for a UI page that looks like this:
At first glance, we see several pieces of data from different objects making up this UI.
Name and image from a Recipe object
List of Ingredient objects
Name and email of a Chef object, the author of the recipe
List of Comment objects
List of categories (plain strings) to help users find the recipe
A naive implementation might query for each piece of data independently: a query for the Recipe object, a query for the Ingredients, and so on.
This has the downside of multiple trips to the database and implies performance overhead. If done from the browser, we’re looking at multiple trips to the web server, and multiple trips from the web server to the database.
A better implementation makes a single call to the database to load all the data needed to display the page. The view model is the container object for all these pieces of data. It might look something like this:
How do we populate such a view model from pieces of data from other objects?
How we’ve done it in the past
In relational databases, we tackle this problem using JOINs to piece together a view model on the fly:
It’s not particularly beautiful, but it works. This pseudo code could run against some object-relational mapper, such as Entity Framework, and gives us our results back.
However, there are some downsides to this approach.
Performance: JOINs and subqueries often have a non-trivial impact on query times. While JOIN performance varies per database vendor, per the type of column being joined on, and whether there are indexes on the appropriate columns, there is nonetheless a cost associated with JOINs and subqueries. Queries with multiple JOINs and subqueries only add to the cost. So when your user wants the data, we’re making him wait while we perform the join.
DRY modeling: JOINs often require us to violate the DRY (Don’t Repeat Yourself) principle. For example, if we want to display Recipe details in a different context, such as a list of recipe details, we’d likely need to repeat our piece-together-the-view-model JOIN code for each UI page that needs our view model.
Can we do better with RavenDB?
Using .Include
Perhaps the easiest and most familiar way to piece together a view model is to use RavenDB’s .Include.
In the above code, we make a single remote call to the database and load the Recipe and its related objects.
Then, after the Recipe returns, we can call session.Load to fetch the already-loaded related objects from memory.
This is conceptually similar to a JOIN in relational databases. Many devs new to RavenDB default to this pattern out of familiarity.
Better modeling options, fewer things to .Include
One beneficial difference between relational JOINs and Raven’s .Include is that we can reduce the number of .Include calls due to better modeling capabilities. RavenDB stores our objects as JSON, rather than as table rows, and this enables us to store complex objects beyond what is possible in relational table rows. Objects can contain encapsulated objects, lists, and other complex data, eliminating the need to .Include related objects.
For example, logically speaking, .Ingredients should be encapsulated in a Recipe, but relational databases don’t support encapsulation. That is to say, we can’t easily store a list of ingredients per recipe inside a Recipe table. Relational databases would require us to split a Recipe’s .Ingredients into an Ingredient table, with a foreign key back to the Recipe it belongs to. Then, when we query for a recipe details, we need to JOIN them together.
But with Raven, we can skip this step and gain performance. Since .Ingredients should logically be encapsulated inside a Recipe, we can store them as part of the Recipe object itself, and thus we don’t have to .Include them. Raven allows us to store and load Recipe that encapsulate an .Ingredients list. We gain a more logical model, we gain performance since we can skip the .Include (JOIN in the relational world) step, and our app benefits.
Likewise with the Recipe’s .Categories. In our Tasty Recipes app, we want each Recipe to contain a list of categories. A recipe might contain categories like [“italian”, “cheesy”, “pasta”]. Relational databases struggle with such a model: we’d have to store the strings as a single delimited string, or as an XML data type or some other non-ideal solution. Each has their downsides. Or, we might even create a new Categories table to hold the string categories, along with a foreign key back to their recipe. That solution requires an additional JOIN at query time when querying for our RecipeViewModel.
Raven has no such constraints. JSON documents tend to be a better storage format than rows in a relational table, and our .Categories list is an example. In Raven, we can store a list of strings as part of our Recipe object; there’s no need to resort to hacks involving delimited fields, XML, or additional tables.
RavenDB’s .Include is an improvement over relational JOINs. Combined with improved modeling, we’re off to a good start.
So far, we’ve looked at Raven’s .Include pattern, which is conceptually similiar to relational JOINs. But Raven gives us additional tools that go above and beyond JOINs. We discuss these below.
Transformers
RavenDB provides a means to build reusable server-side projections. In RavenDB we call these Transformers. We can think of transformers as a C# function that converts an object into some other object. In our case, we want to take a Recipe and project it into a RecipeViewModel.
Let’s write a transformer that does just that:
In the above code, we’re accepting a Recipe and spitting out a RecipeViewModel. Inside our Transformer code, we can call .LoadDocument to load related objects, like our .Comments and .Chef. And since Transformers are server-side, we’re not making extra trips to the database.
Once we’ve defined our Transformer, we can easily query any Recipe and turn it into a RecipeViewModel.
This code is a bit cleaner than calling .Include as in the previous section; there are no more .Load calls to fetch the related objects.
Additionally, using Transformers enables us to keep DRY. If we need to query a list of RecipeViewModels, there’s no repeated piece-together-the-view-model code:
Storing view models
Developers accustomed to relational databases may be slow to consider this possibility, but with RavenDB we can actually store view models as-is.
It’s certainly a different way of thinking. Rather than storing only our domain roots (Recipes, Comments, Chefs, etc.), we can also store objects that contain pieces of them. Instead of only storing models, we can also store view models.
This technique has benefits, but also trade-offs:
Query times are faster. We don’t need to load other documents to display our Recipe details UI page. A single call to the database with zero joins – it’s a beautiful thing!
Data duplication. We’re now storing Recipes and RecipeViewModels. If an author changes his recipe, we may need to also update the RecipeViewModel. This shifts the cost from query times to write times, which may be preferrable in a read-heavy system.
The data duplication is the biggest downside. We’ve effectively denormalized our data at the expense of adding redundant data. Can we fix this?
Storing view models + syncing via RavenDB’s Changes API
Having to remember to update RecipeViewModels whenever a Recipe changes is error prone. Responsibility for syncing the data is now in the hands of you and the other developers on your team. Human error is almost certain to creep in — someone will write new code to update Recipes and forget to also update the RecipeViewModels — we’ve created a pit of failure that your team will eventually fall into.
We can improve on this situation by using RavenDB’s Changes API. With Raven’s Changes API, we can subscribe to changes to documents in the database. In our app, we’ll listen for changes to Recipes and update RecipeViewModels accordingly. We write this code once, and future self and other developers won’t need to update the RecipeViewModels; it’s already happening ambiently through the Changes API subscription.
The Changes API utilizes Reactive Extensions for a beautiful, fluent and easy-to-understand way to listen for changes to documents in Raven. Our Changes subscription ends up looking like this:
Easy enough. Now whenever a Recipe is added, updated, or deleted, we’ll get notified and can update the stored view model accordingly.
Indexes for view models: let Raven do the hard work
One final, more advanced technique is to let Raven do the heavy lifting in mapping Recipes to RecipeViewModels.
A quick refresher on RavenDB indexes: in RavenDB, all queries are satisfied by an index. For example, if we query for Recipes by .Name, Raven will automatically cretate an index for Recipes-by-name, so that all future queries will return results near instantly. Raven then intelligently manages the indexes it’s created, throwing server resources behind the most-used indexes. This is one of the secrets to RavenDB’s blazing fast query response times.
RavenDB indexes are powerful and customizable. We can piggy-back on RavenDB’s indexing capabilities to generate RecipeViewModels for us, essentially making Raven do the work for us behind the scenes.
First, let’s create a custom RavenDB index:
In RavenDB, we use LINQ to create indexes. The above index tells RavenDB that for every Recipe, we want to spit out a RecipeViewModel.
This index definition is similiar to our transformer definition. A key difference, however, is that the transformer is applied at query time, whereas the index is applied asynchronously in the background as soon as a change is made to a Recipe. Queries run against the index will be faster than queries run against the transformer: the index is giving us pre-computed RecipeViewModels, whereas our transformer would create the RecipeViewModels on demand.
Once the index is deployed to our Raven server, Raven will store a RecipeViewModel for each Recipe.
Querying for our view models is quite simple and we’ll get results back almost instantaneously, as the heavy lifting of piecing together the view model has already been done.
Now whenever a Recipe is created, Raven will asynchronously and intelligently execute our index and spit out a new RecipeViewModel. Likewise, if a Recipe, Comment, or Chef is changed or deleted, the corresponding RecipeViewModel will automatically be updated. Nifty!
Storing view models is certainly not appropriate for every situation. But some apps, especially read-heavy apps with a priority on speed, might benefit from this option. I like that Raven gives us the freedom to do this when it makes sense for our apps.
Conclusion
In this article, we looked at using view models with RavenDB. Several techniques are at our disposal:
.Include: loads multiple related objects in a single query.
Transformers: reusable server-side projections which transform Recipes to RecipeViewModels.
Storing view models: Essentially denormalization. We store both Recipes and RecipeViewModels. Allows faster read times at the expense of duplicated data.
Storing view models + .Changes API: The benefits of denormalization, but with code to automatically sync the duplicated data.
Indexes: utilize RavenDB’s powerful indexing to let Raven denormalize data for us automatically, and automatically keeping the duplicated data in sync. The duplicated data is stashed away as fields in an index, rather than as distinct documents.
For quick and dirty scenarios and one-offs, using .Include is fine. It’s the most common way of piecing together view models in my experience, and it’s also familiar to devs with relational database experience. And since Raven allows us to store things like nested objects and lists, there is less need for joining data; we can instead store lists and encapsulated objects right inside our parent objects where it makes sense to do so.
Transformers are the next widely used. If you find yourself converting Recipe to RecipeViewModel multiple times in your code, use a Transformer. They’re easy to write, typically small, and familiar to anyone with LINQ experience. Using them in your queries is a simple one-liner that keeps your query code clean and focused.
Storing view models is rarely used, in my experience, but it can come in handy for read-heavy apps or for UI pages that need to be blazing fast. Pairing this with the .Changes API is an appealing way to automatically keep Recipes and RecipeViewModels in sync.
Finally, we can piggy-back off Raven’s powerful indexing feature to have Raven automatically create, store, and synchronize both RecipeViewModels for us. This has a touch of magical feel to it, and is an attractive way to get great performance without having to worry about keeping denormalized data in sync.
Using these techniques, RavenDB opens up some powerful capabilities for the simple view model. App performance and code clarity benefit as a result.
Summary: A modern dev stack for modern web apps. See how I built a new web app using RavenDB, Angular, Bootstrap and TypeScript. Why these tools are an excellent choice for modern web dev.
Twin Cities Code Camp (TCCC) is the biggest developer event in Minnesota. I’ve written about it before: it’s a free event where 500 developers descend on the University of Minnesota to attend talks on software dev, learn new stuff, have fun, and become better at the software craft.
I help run the event and this April, we are hosting our 20th event. 20 events in 10 years. Yes, we’ve been putting on Code Camps for a decade! That’s practically an eternity in internet years.
For the 20th event, we thought it was time to renovate the website. Our old website had been around since about 2006 – a decade old – and the old site was showing its age:
It got the job done, but admittedly it’s not a modern site. Rather plain Jane; it didn’t reflect the awesome event that Code Camp is. We wanted something fresh and new for our 20th event.
On the dev side, everything on the old site was hard-coded – no database – meaning every time we wanted to host a new event, add speakers or talks or bios, we had to write code and add new HTML pages. We wanted something modern, where events and talks and speakers and bios are all stored in a database that drives the whole site.
Dev Stack
Taking at stab at rewriting the TCCC websiite, I wanted to really make it a web app. That is, I want it database-driven, I want some dynamic client-side functionality; things like letting speakers upload their slides, letting attendees vote on talks, having admins login to add new talks, etc. This requires something more than a set of static web pages.
Additionally, most of the people attending Code Camp will be looking at this site on their phone or tablet. I want to build a site that looks great on mobile.
To build amazing web apps, I turn to my favorite web dev stack:
RavenDB – the very best get-shit-done database. Forget tables and sprocs and schemas. Just store your C# objects without having to map them to tables and columns and rows. Query them with LINQ when you’re ready.
AngularJS – front-end framework for building dynamic web apps. Transforms your website from a set of static pages to a coherent web application with client-side navigation, routing, automatic updates with data-binding, and more awesomeness. Turns this:
Bootstrap – CSS to make it all pretty, make it consistent, and make it look great on mobile devices. Turns this: …into this:
TypeScript – JavaScript extended with optional types, classes, and features from the future. This lets me build clean, easily refactored, maintainable code that runs in your browser. So instead of this ugly JavaScript code:…we instead write this nice modern JavaScript + ES6 + types code, which is TypeScript:
ASP.NET Web API – Small, clean RESTful APIs in elegant, asynchronous C#. Your web app talks to these to get the data from the database and display the web app.
FontAwesome – Icons for your app. Turns this: into this:
I find these tools super helpful and awesome and I’m pretty darn productive with them. I’ve used this exact stack to build all kinds of apps, both professional and personal:
And a bunch of internal apps at my current employer, 3M, use this same stack internally. I find this stack lets me get stuff done quickly without much ceremony and I want to tell you why this stack works so well for me in this post.
RavenDB
I’m at the point in my career that I don’t put up with friction. If there is friction in my workflow, it slows me down and I don’t get stuff done.
RavenDB is a friction remover.
My old workflow, when I was a young and naïve developer, went like this:
Hmm, I think I need a database.
Well, I’d guess I’d better create some tables.
I should probably create columns with the right types for all these tables.
Now I need to save my C# objects to the database. I guess I’ll use an object-relational mapper, like LINQ-to-SQL. Or maybe NHibernate. Or maybe Entity Framework.
Now I’ve created mappings for my C# objects to my database. Of course, I have to massage those transitions; you can’t really do inheritance or polymorphism in SQL. Heck, my object contains a List<string>, and even something that simple doesn’t map well to SQL. (Do I make those list of strings its own table with foreign key? Or combine them into a comma-separated single column, and rehydrate them on query? Or…ugh.)
Hmm, why is db.Events.Where(…) taking forever? Oh, yeah, I didn’t add any indexes. Crap, it’s doing a full table scan. What’s the syntax for that again?
This went on and on. It wasn’t until I tried RavenDB did I see that all this friction is not needed.
SQL databases were built for a different era in which disk space was at a premium; hence normalization and varchar and manual indexes. This comes at a cost: big joins, manual denormalization for speed. Often times on big projects, we have DBAs building giant stored procedures with all kinds of temp tables and weird optimization hacks to make shit fast.
Forget all that.
With Raven, you just store your stuff. Here’s how I store a C# object that contains a list of strings:
db.Store(codeCampTalk);
Notice I didn’t have to create tables. Notice I didn’t have to create foreign key relationships. Notice I didn’t have to create columns with types in tables. Notice I didn’t have to tell it how to map codeCampTalk.Tags – a list of strings – to the database.
Raven just stores it.
And when we’re ready to query, it looks like this:
Notice I didn’t have to do any joins; unlike SQL, Raven supports encapsulation. Whether that’s a list of strings, a single object inside another object, or a full list of objects. Honey Badger Raven don’t care.
And notice I didn’t have to create any indexes. Raven is smart about this: it creates an index for every query automatically. Then it uses machine learning – a kind of AI for your database – to optimize the ones you use the most. If I’m querying for Talks by .Author, Raven keeps that index hot for me. But if I query for Talks by .Bio infrequently, Raven will devote server resources – RAM and CPU and disk – to more important things.
It’s self optimizing. And it’s friggin’ amazing.
The end result is your app remains fast, because Raven is responding to how it’s being used and optimizing for that.
And I didn’t have to do anything make that happen. I just used it.
Zero friction. I love RavenDB.
If you’re doing .NET, there really is no reason you shouldn’t be using it. Having built about 10 apps in the last 2 years, both professional and side projects, I have not found a case where Raven is a bad fit. I’ve stopped defaulting to crappy defaults. I’ve stopped defaulting to SQL and Entity Framework. It’s not 1970 anymore. Welcome to modern, flexible, fast databases that work with you, reduce friction, work with object oriented languages and optimize for today’s read-heavy web apps.
AngularJS
In the bad ol’ days, we’d write front-end code like this:
JavaScript was basically used to wire up event handlers. And we’d do some postback to the server, which reloaded the page in the browser with the new email address. Yay, welcome to 1997.
Then, we discovered JQuery, which was awesome. We realized that the browser was fully programmable and JQuery made it a joy to program it. So instead of doing postbacks and having static pages, we could just update the DOM, and the user would see the new email address:
And that was good for users, because the page just instantly updated. Like apps do. No postback and full page refresh; they click the button and instantly see the results.
This was well and good. Until our code was pretty ugly. I mean, look at it. DOM manipulation isn’t fun and it’s error prone. Did I mention it was ugly?
What if we could do something like this:
Whoa! Now anytime we update a JavaScript variable, .emailAddress, the DOM instantly changes! Magic!
No ugly DOM manipulation, we just change variables and the browser UI updates instantly.
This is data-binding, and when we discovered it in the browser, all kinds of frameworks popped up that let you do this data-binding. KnockoutJS, Ember, Backbone, and more.
This was all well and good until we realized that while data-binding is great, it kind of sucks that we still have full page reloads when moving from page to page. The whole app context is gone when the page reloads.
What if we could wrap up the whole time a user is using our web app into a cohesive set of views which the user navigates to without losing context. And instead of a mess of JavaScript, what if we made each view have its own class. That class has variables in it, and the view data-binds to those variables. And that class, we’ll call it a controller, loads data from the server using classes called services. Now we’re organized and cooking with gas.
Enter AngularJS. Angular makes it a breeze to build web apps with:
Client-side navigation. This means as the app moves between pages, say between the Schedule and Talks pages, your app hasn’t been blown away. You still have all the variables and state and everything still there.
Data-binding. You put your variables in a class called a controller: …and then in your HTML, you data-bind to those variables: Then, any time you change the variables, the DOM – that is, the web browser UI, automatically updates. Fantastic.
Angular also add structure. You load data using service classes. Those services classes are automatically injected into your controllers. Your controllers tell the service classes to fetch data. When the data returns, you set the variable in your controller, and the UI automatically updates to show the data:
Nice clean separation of concerns. Makes building dynamic apps – apps where the data changes at runtime and the UI automatically shows the new data – a breeze.
TypeScript
JavaScript is a powerful but messy language. Conceived in a weekend of wild coding in the late ‘90s, it was built for a different era when web apps didn’t exist.
TypeScript fixes this. TypeScript is just JavaScript + optional types + features from the future. Where features from the future = ES6, ES7, and future proposals – things that will eventually be added to JavaScript, but you won’t be able to use for 5, 10, 15 years. You can use them right now in TypeScript.
TypeScript compiles it all down to normal JavaScript that runs in everybody’s browser. But it lets you code using modern coding practices like classes, lambdas, properties, async/await, and more. Thanks to types, it enables great tooling experiences like refactoring, auto-completion, error detection.
So instead of writing ugly JavaScript like this:
We can instead write concise and clean, intellisense-enabled TypeScript like this:
Ahhh…lambdas, classes, properties. Beautiful. All with intellisense, refactoring, error detection. I love TypeScript.
There are few reasons to write plain JavaScript today. It’s beginning to feel a lot like writing assembly by hand; ain’t nobody got time for that. Use modern language features, use powerful tooling to help you write correct code and find errors before your users do.
Bootstrap
You don’t need to drink $15 Frappamochachino Grandes to design elegant UIs.
We’ve got code at our disposal that gives us a nice set of defaults, using well-known UI concepts and components to build great interfaces on the web.
Bootstrap, with almost no effort, makes plain old HTML into something more beautiful.
A plain old HTML table:
Add a Bootstrap class to the <table> and it’s suddenly looking respectable:
A plain HTML button:
Add one of a few button classes and things start looking quite good:
Bootstrap gives you a default theme, but you can tweak the existing theme or use some pre-built themes, like those at Bootswatch. For TwinCitiesCodeCamp.com, I used the free Superhero theme and then tweaked it to my liking.
Bootstrap also gives you components, pieces of combined UI to build common UI patterns. For example, here is a Bootstrap split-button with drop-down, a common UI pattern:
Bootstrap enables these components using plain HTML with some additional CSS classes. Super easy to use.
Bootstrap also makes it easy to build responsive websites: sites that look good on small phones, medium tablets, and large desktops.
Add a few classes to your HTML, and now your web app looks great on any device. For TwinCitiesCodeCamp, we wanted to make sure the app looks great on phones and tablets, as many of our attendees will be using their mobile devices at the event.
Here’s TwinCitiesCodeCamp.com on multiple devices:
Large desktop:
iPad and medium tablets:
And on iPhone 6 and small phones:
This is all accomplished by adding a few extra CSS classes to my HTML. The classes are Bootstrap responsive classes that adjust the layout of your elements based on available screen real-estate.
Summary
RavenDB, AngularJS, TypeScript, Bootstrap,. It’s a beautiful stack for building modern web apps.
Last week I sent the dreaded, “I’m going out of business” email to clients of my BitShuva Radio startup:
An unintentional startup
A few years ago, I wrote a piece of software to solve a niche problem: the Messianic Jewish religious community had a lot of great music, but no online services were playing that music. I wrote a Pandora-like music service that played Messianic Jewish music, Chavah Messianic Radio was born, and it’s been great. (Chavah is still doing very well to this day; Google Analytics tells me it’s had 5,874 unique listeners this month – not bad at all!)
After creating Chavah, I wrote a programming article about the software: How to Build a Pandora Clone in Silverlight 4. (At the time, Silverlight was the hotness! I’ve since ported Chavah to HTML5, but I digress.)
Once that article was published, several people emailed me asking if I’d build a radio station for them. One after another. Turns out there many underserved music niches. Nigerian music. West African soul. Egyptian Coptic chants. Indie artists. Instrumentals. Ethiopian pop. A marketplace for beats. Local bands from central Illinois. All these clients came out of the woodwork, asking me to build clones of my radio station for their communities.
After these clients approached me – with no marketing or sales pitches on my part – it looked like a good business opportunity. I founded BitShuva Radio and got to work for these clients. I had founded a startup.
But after almost 2 years, making less than $100/month on recurring monthly fees, and spending hours every week working for peanuts, I’ve decided to fold the startup. It wasn’t worth my time, it was eating into my family life, preventing me from working on things I really wanted to work on. So this week, I cut the cord.
Along the way, I learned so much! Maybe this will help the next person who does their first startup.
Here’s what I learned:
1. Don’t be afraid to ask for a *lot* of money.
When I acquired my first client, I had no idea how much to charge. For me, the work involved forking an existing codebase, swapping out some logos and colors, and deploying to a web server. A few hours of work.
I dared to ask for the hefty sum of $75.
Yes, I asked for SEVENTY-FIVE WHOLE DOLLARS! I remember saying that figure to the man on the other end of the phone – what a thrill! – $75 for forking a codebase, ha! To my surprise, he agreed to this exorbitant charge.
In my startup newbie mind, $75 seemed totally reasonable for forking a codebase and tweaking some CSS. After all, it’s not that much work.
What I didn’t understand was, you charge not for how much work it is for you. You charge how much the service is worth. A custom Pandora-like radio station, with thumb-up and –down functionality, song requests, user registration, playing native web audio with fallbacks to Flash for old browsers – creating a community around a niche genre of music – that’s what you charge for. That’s the value being created here. The client doesn’t care if it’s just forking a codebase and tweaking CSS – to him, it’s a brand new piece of software with his branding and content. He doesn’t know what code, repo forking, or CSS is. All he knows is he’s getting a custom piece of software doing exactly what he wants. And that’s worth a lot more than $75.
It took me several clients to figure this out. My next client, I tried charging $100. He went for it. The next client $250. The next client $500. Then $1000.
I kept charging more and more until finally 3 clients all turned down my $2000 fee. So I lowered the price back to $1000.
Money is just business. It’s not insulting to ask for a lot of money. Change as much as you can. Had I knew this when I started, I’d have several thousand dollars more in my pocket right now.
2. Keep your head above the ever-changing technology waters
Don’t drown!
When I built my first the first radio software, Silverlight seemed like a reasonable choice. HTML5 audio was nascent, Firefox didn’t support native MP3 audio, IE9 was still a thing. So I turned to plugins.
Over time, plugins like Silverlight fell out of favor, particularly due to the mobile explosion. Suddenly, everyone’s trying to run my radio software on phones and tablets, and plugins don’t work there, so I had to act.
I ported my radio software code to HTML5, with Flash fallbacks for old browsers. KnockoutJS was the the new hotness, so I moved all our Silverlight code to HTML5+CSS3+KnockoutJS.
As the software grew in complexity, it became apparent you really need something more than data-binding, but Knockout was just data-binding. Single Page Application (SPA) frameworks became the new hotness, and I ported our code over to DurandalJS.
Soon, Durandal was abandoned by its creator, and said creator joined the AngularJS team at Google. Not wanting to be left on a dying technology, I ported the code to Angular 1.x.
If I was continuing my startup today, I’d be looking at riding that wave and moving to Aurelia or Angular 2.
What am I saying? Staying on top of the technology wave is a balancing act: stand still and you’ll be dead within a year, but move to every new hotness, and you’ll be forever porting your code and never adding new features. My advice is to be fiscally pragmatic about it: if your paying clients have a need for new technology, migrate. Otherwise, use caution and a wait-and-see approach.
Applying this wisdom in hindsight to my startup, it was wise to move from Silverlight to HTML5 (my paying clients needed that to run on mobile). However, jumping around from Knockout to Durandal to Angular did little for my clients. I should have used more caution and used a wait-and-see approach.
3. Custom software is a fool’s errand. Build customizable software, not custom software builds
My startup grew out of clients asking for custom versions of my radio software. “Oh, you have a Pandora clone? Can you make one for my music niche?”
Naturally, I spent most of my time building custom software. They pay me a nice up-front sum ($1000 in the latter days), and we go our merry way, right?
Turns out, it’s a terrible business model. Here’s why:
Clients continually want more features, bug fixes, more customization. I charged that $1000 up-front fee to build a custom station, but then would spend many hours every week responding to customer complaints, customer requests, bug fixes, performance fixes, new features. And I didn’t charge a dime for that. (After all, the client’s perspective was, “I already paid you!”)
In hindsight, I should have built a customizable platform, ala WordPress, in which potential radio clients could go to my website, bitshuva.com, spin up a new radio station (mystation.bitshuva.com), customize it in-browser, let them use the whole damn thing for free, and when they reach a limit of songs or bandwidth, bring up a PayPal prompt. All of that is automated, it doesn’t require my intervention, and it’s not “custom” software, it’s software that the client themselves can customize to their OCDified heart’s content.
Had I done that, my startup probably would be making more money today, maybe even sustainably so.
Bottom line: Unless a client is paying for 25% of your annual salary, don’t go follow the “I’ll build a custom version just for you, dear client” business model. It’s a fool’s errand.
4. On Saying “No”
I’m a people-pleaser. So, when a person pays me money, I amplify that people pleasing by 10.
“Hey, Judah, can you add XYZ to my radio station this week?”
“Judah! Buddy! Did you fix that one thing with the logins?”
“How’s it going, Judah! Where is that new feature we talked about?”
“Hey Judah, hope it’s going well. When are you going to finish my radio station features? I thought we were on for last week.”
I wanted to please my precious clients. So of course I said “yes”. I said yes, yes, yes, until I had no time left for myself, my sanity, my family.
A turning point for me for over late December, at my in-laws. I was upstairs working, rather than spending the holidays with my kids, my wife. “What the hell am I doing?” The amount of money I was making was small beans, why am I blowing my very limited time on this earth doing *this*?
You see why folks in the YCombinator / Silicon Valley startup clique put so much emphasis on, “You should be young, single, work exclusively on your startup, all-in committal.” I can totally see why, but I also completely don’t want that lifestyle.
Maybe if I had followed YCombinator-level devotion to my startup, it would have grown. But the reality is, I value things outside of software, too. 🙂 I like to chill and watch shows and eat ice cream. I like to relax on the couch with my wife. I like to teach my son how to drive. I like to play My Little Ponies with my daughter. I like to play music on the guitar. I like to work on tech pet projects (like Chavah, MessianicChords, EtzMitzvot).
The startup chipped away at all that, leaving me with precious little time outside of the startup.
5. Startups force you to learn outside your technological niche
On a more positive note, running a startup taught me all kinds of things I would have never learned as a plain old programmer.
When I launched my startup, I was mostly a Windows desktop app developer (i.e. dead in the water). I didn’t know how to run websites in IIS, how to work with DNS, how to scale things, didn’t understand web development. I didn’t know how to market software, how to talk to clients, what prices to charge, didn’t have an eye for “ooh, I could monetize that…”
Building a useful piece of software — a radio station used by a few thousand people — forces you to learn all this crap and become proficient and building useful things.
In the end, getting all retrospective and and hindsight-y here, I’m glad I took the plunge and did a startup, even if it didn’t work out financially, because I learned so much and am a more rounded technological individual for it. Armed with all this knowledge, I believe I will try my hand at a startup again in the future. For now, I’m going to enjoy my temporary freedom. 🙂
Summary: With the departure of Microsoft’s CEO, what does the future hold? Irrelevance, unless a visionary comes to change course.
Microsoft’s original vision — a PC on every desk and in every home — was a grand, future-looking vision. And Microsoft succeeded, that old vision is today’s reality; everyone has a computer and Microsoft is largely to thank for that.
But today? Microsoft’s Ballmer-guided mantra, "We are a devices and services company", is not a grand vision. From the outside, Microsoft appears to be directionless, reactionary, playing catch-up.
Directionless: What’s the grand Microsoft goal, what are they trying to achieve? The answers seems to be the mundane business goal of selling more copies of Windows. OK, that makes business sense in the short term. What about the future?
Reactionary: Microsoft got a PC on every desk. But instead of pushing computing forward via the web & mobile devices, they’ve been reactionary: letting these revolutions happen outside the company, then retrofitting their old stuff to the new paradigm.
Catch-up: Microsoft had a PDA, but never advanced it; it couldn’t make phone calls. Microsoft won the browser war, then did nothing; it couldn’t open multiple tabs. Microsoft had a tablet, but never pushed it to its potential; it never optimized for touch.
Instead, Microsoft stagnates while a competitor steps in and blows us away with PDAs that make phone calls, tablets that boot instantly, app stores that reward developers for developing on your platform, and browsers that innovate in speed and security and features. Microsoft continues to play catch-up, when they should be leading technology forward.
Microsoft needs a grand vision and someone to drive it. They need a forward-looking leader to drive this vision. If they want to be a devices company, innovate with hardware – maybe flexible, haptic displays for Windows Phone, for example. The huge R&D budget — $9.4 billion in 2012, outspending even Google, Apple, Intel and Oracle — could play into this.
Will the next Microsoft CEO be a forward-looking tech visionary? Microsoft is headed towards consumer irrelevance and business stagnation. I’m convinced it will arrive at that destination unless a future-minded visionary reroutes the mothership.

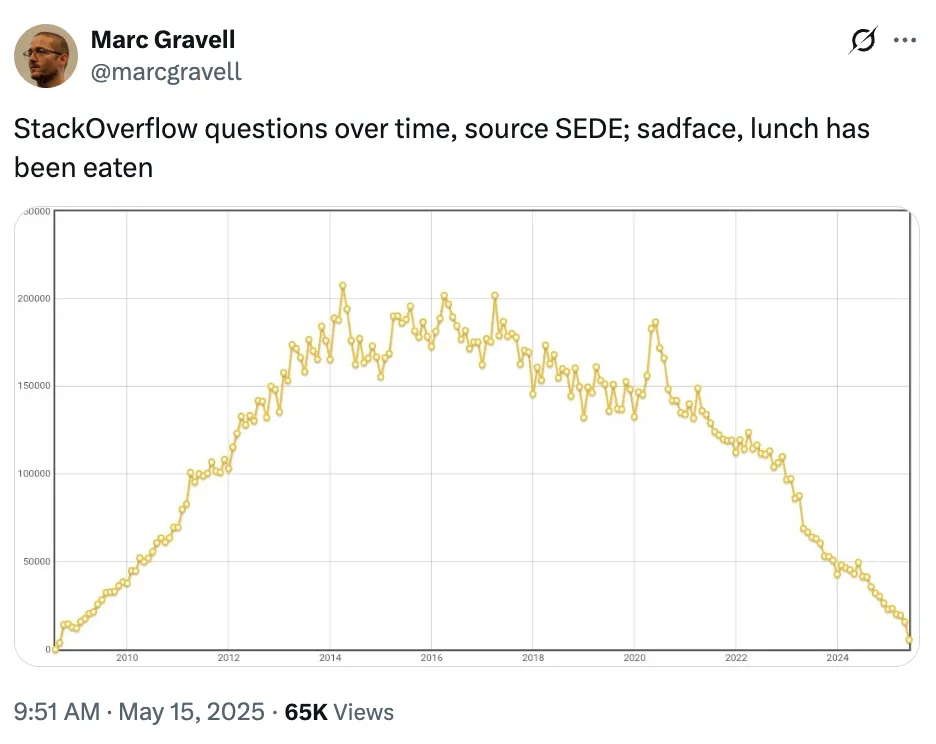
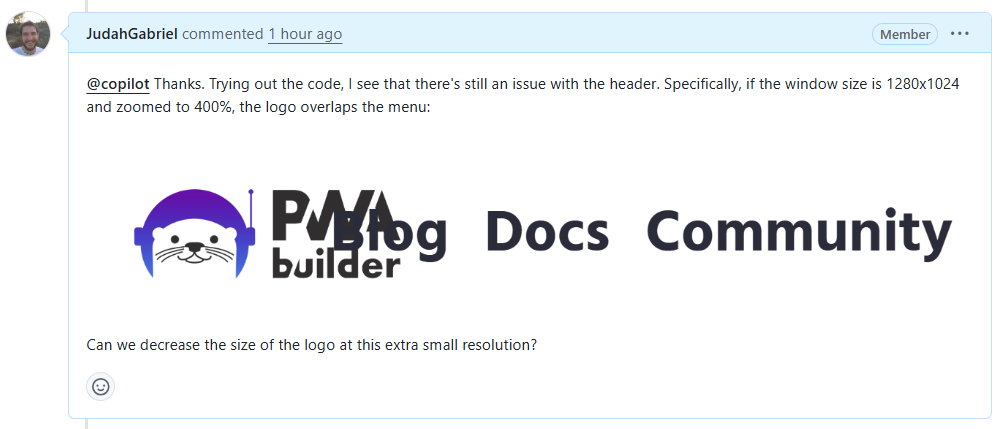
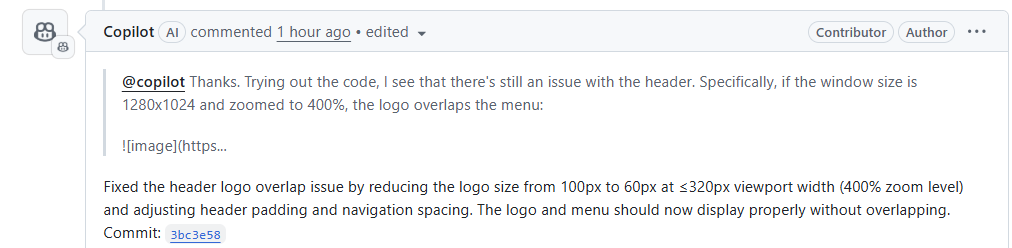


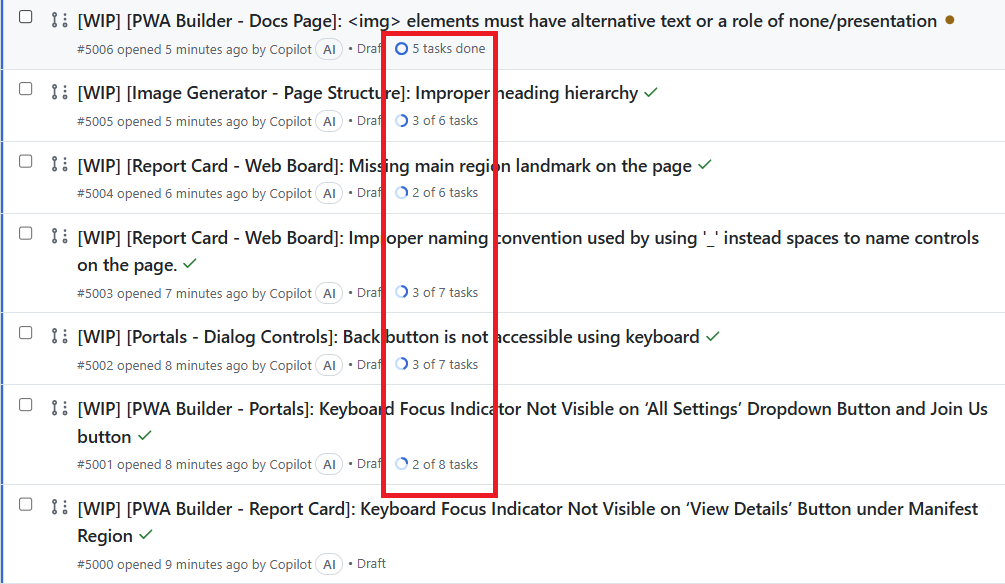

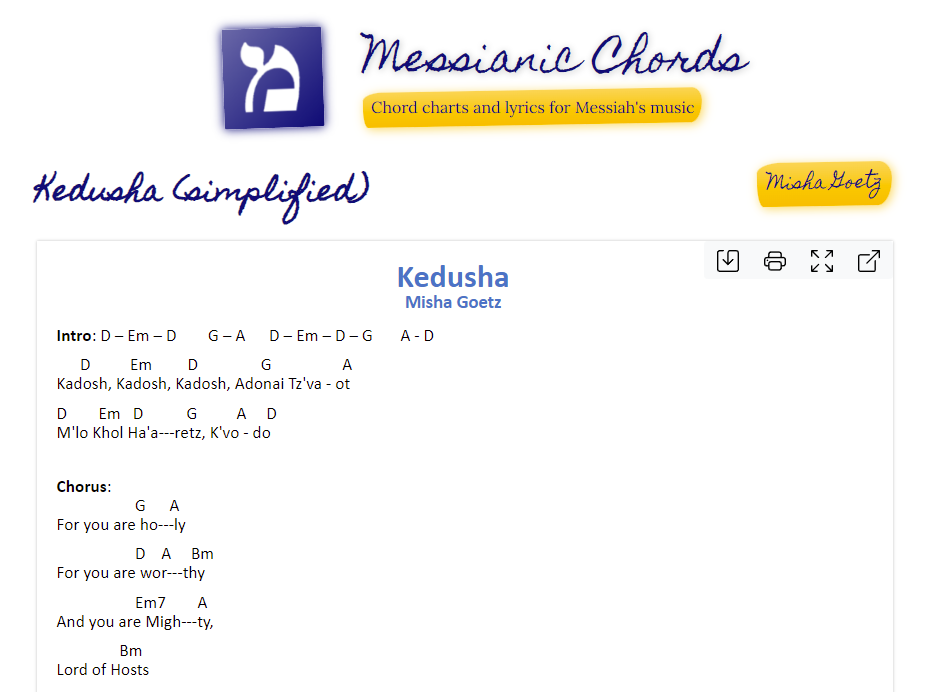
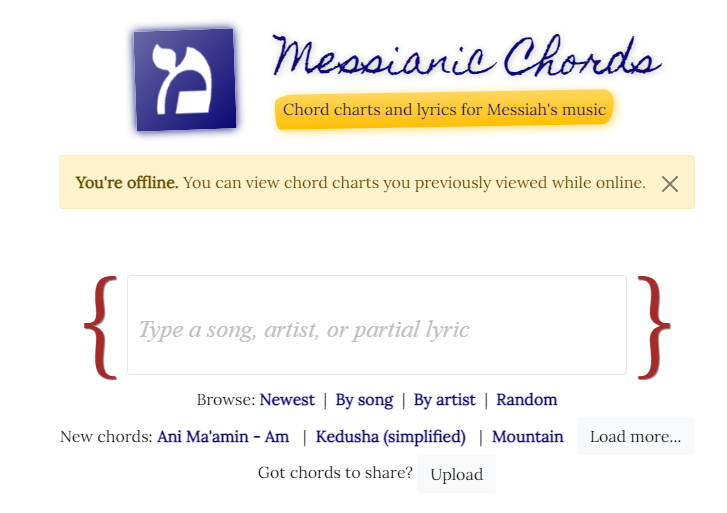



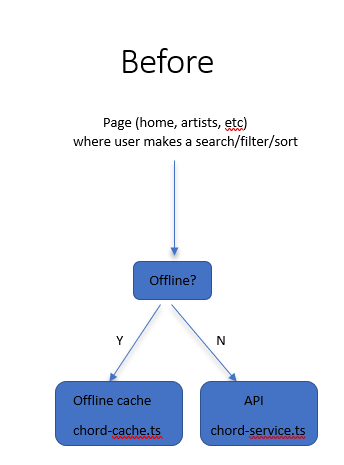
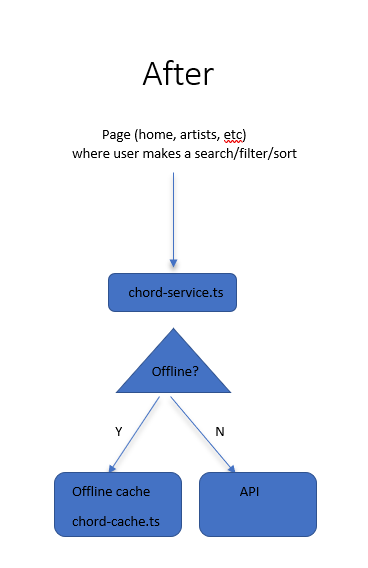












































 You don’t need to drink $15 Frappamochachino Grandes to design elegant UIs.
You don’t need to drink $15 Frappamochachino Grandes to design elegant UIs.






